![Fun with Tags]() Ok, working with vSphere Tags is basically not funny, but it can be extremely helpful.
Ok, working with vSphere Tags is basically not funny, but it can be extremely helpful.
And to be honest, there is another explanation why I decided to use this title for the blog post. If you know Big Bang Theory you definitely know why ![🙂]()
But let us focus on the topic “VMware vSphere Tags”…
The possibility to apply tags to objects in the vSphere inventory was already introduced with vSphere 5.1. Tags are an enhancement of the legacy “Custom Attributes” and are a charming feature you should definitely use.
It enables you to add valuable information to the inventory objects and make them searchable and sortable. So you can add a tag with the responsible person or department to a virtual machine. Or if you classify your virtual machines to meet Service Level Agreements (SLAs), you can provide the necessary information in a tag. Furthermore, they are extremely helpful and powerful if you use them in scripts.
So let’s start with some basics:
 What is a Tag?
What is a Tag?
A tag is a label that you can apply to vSphere inventory objects like virtual machines, hosts, datastores,… Every tag is assigned to a category.
What is a Category?
A category contains one or more tags and groups them together. A category also specifies if you can assign multiple tags out of the category to an object or only one.
For better understanding here an every-day-work example:
You want to classify your virtual machines into three different availability tiers: Production, DEV, and Test
Create a new category called “Availability” and choose “one tag per object” (because if a virtual machine is classified as “Production” it cannot be “Test” or “DEV”). In the wizard, you can also specify if the new category is associable only with dedicated object types or all:

By the way, if you try to create categories or tags within the “old” vSphere Client, then I have to disappoint you. Tags and Categories are only available using the Web client ![🙂]()
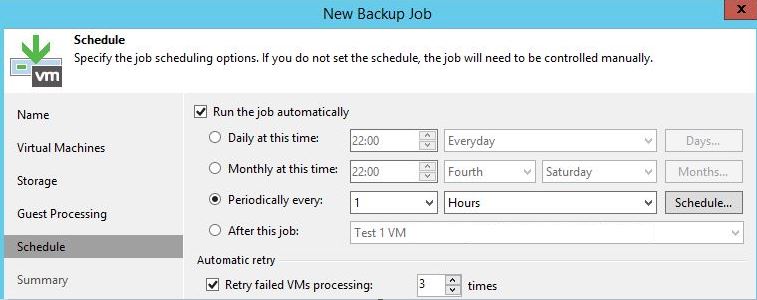
In the next step, you will create three different tags called Production, DEV, and Test and assign them to the previously created category “Availability”:

Now everything is prepared to classify your virtual machines into the new created Tiers. Select a VM in the Web client and search for the field “Tags”. Select “Assign” and add the accurate tag:

If you play around with Tags and Categories within the Web client, you will find out quickly how useful this feature is. So you can use the Filter to display eg. only VMs classified as “Production”:

Managing Tags and Categories with PowerCLI
One of the best things about tags and categories is, that you can manage them with PowerCLI!
Get-TAG
So let’s start with the Get-Tag to list all defined tags:

Get-VM -Tag
To list all VMs with the Tag “Test” you can use the command:
Get-VM -Tag “Test”

It is easy to manage tags with PowerCLI, isn’t it? But there are more commandlets available. Give these ones a try:
Get-TagAssignment
This command lists all assigned tags for different entities.
If you want to list eg. all tags assigned to a dedicated ESXi host just trigger:
Get-TagAssignment -Entity “your_ESXi_Host”
New-TagAssignment
With this command, you can assign a tag to an object.
For example to assign the tag “DEV” to the VM “DEV_VM1” use:
New-TagAssignment -Tag “DEV” -Entity “DEV_VM1”
Remove-TagAssignment
Very surprising this command enables you to remove an assigned tag from an object. If you want to remove the tag from the VM configured above just try the following:
Get-VM “DEV-VM1” |Get-TagAssignment |Remove-TagAssignment
If there are more tags assigned to the VM you will be asked for every single tag if you want to remove it or not.
Appetite for more?
If you like to work with the commands presented above, take a look at all the other available ones. The following command will list them all for you:
get-command -PSSnapin vmware.vimautomation.core *tag*

How to assign different tags to many virtual machines (using a .csv file)?
When you start to work with categories and tags you will fairly soon need a possibility to assign a tag to a list of virtual machines.
To give you an idea how it works, I will stick to the example from the beginning of this blog post.
The challenge: assign different tags (Test, DEV, Production) out of one category (Availability) to a list of VMs.
- The list:
VM Tier
—————–
MyVM01 DEV
MyVM02 DEV
MyVM03 Test
MyVM04 Production
- Step 1: create a .csv file (eg. vm.csv) with the following content:
VM,Info
MyVM01,DEV
MyVM02,DEV
MyVM03,Test
MyVM04,Production
- Step 2: create the category and tags (if you have not already done it for the example above)
- Step 3: use the following script to assign the tags to your VMs:
$csv = Import-CSV C:\vm.csv
$csv| foreach {
$vm = $_.vm
$tag = $_.info
New-TagAssignment -Tag $tag -Entity $vm
}
- If you are not used to the PowerCLI here some hints that may help you:
save the script above as a .ps1 file
open PowerCLI
connect VI-Server “your_vCenter”
navigate to the path with the .ps1 file
execute the script with the command: .\filename.ps1
Ready for Episode 2 of “Fun with Tags”? Here we go: Tags and Veeam
Fun with Tags, Episode 1: Basics and PowerCLI
Fun with Tags, Episode 2: Tags and Veeam
Der Beitrag Fun with Tags erschien zuerst auf All about virtualization.






























 CloudPhysics vision of Big Data for IT operations may be the answer to questions similar to those above.
CloudPhysics vision of Big Data for IT operations may be the answer to questions similar to those above.
 The Knowledge Base is an inexhaustible source of documented issues, practical experiences, and best practices about VMware’s range of products. Runecast’s idea is, to automatically analyze this data and match it against the configuration and logs of your data center. Pretty cool, isn’t it?
The Knowledge Base is an inexhaustible source of documented issues, practical experiences, and best practices about VMware’s range of products. Runecast’s idea is, to automatically analyze this data and match it against the configuration and logs of your data center. Pretty cool, isn’t it? First, it matches the gathered data of your environment against VMware Knowledge Base articles.
First, it matches the gathered data of your environment against VMware Knowledge Base articles. Here Veeam can support you with the free Veeam Stencils for VMware, Hyper-V and Veeam. Its a collection with all the icons you are looking for when creating diagrams about your IT-infrastructure.
Here Veeam can support you with the free Veeam Stencils for VMware, Hyper-V and Veeam. Its a collection with all the icons you are looking for when creating diagrams about your IT-infrastructure.

 Nice to have: for technically affine users (or better the computer nerds…) they offer an Apple Watch extension of PRTG for iOS. Busy admins can use it to receive push notifications directly to their Apple Watch where ever they are…
Nice to have: for technically affine users (or better the computer nerds…) they offer an Apple Watch extension of PRTG for iOS. Busy admins can use it to receive push notifications directly to their Apple Watch where ever they are…





 What is a Tag?
What is a Tag?